人工智慧技術及應用人才培育計畫 - 人工智慧技術視覺化展示系統
YOLO
You Only Look Once
深度學習 物件偵測
簡介


大家好,我是左左同學。
大家好,我是右右老師。
今天介紹 YOLO 深度學習物件偵測技術!

今天的主角是 YOLO,它是一種物件偵測方法。
特色是速度很快
什麼是 OBJECT DETECTION 物件偵測?
讓電腦使用深度學習技術,分析影片。
找出物件位置,辨識物件。
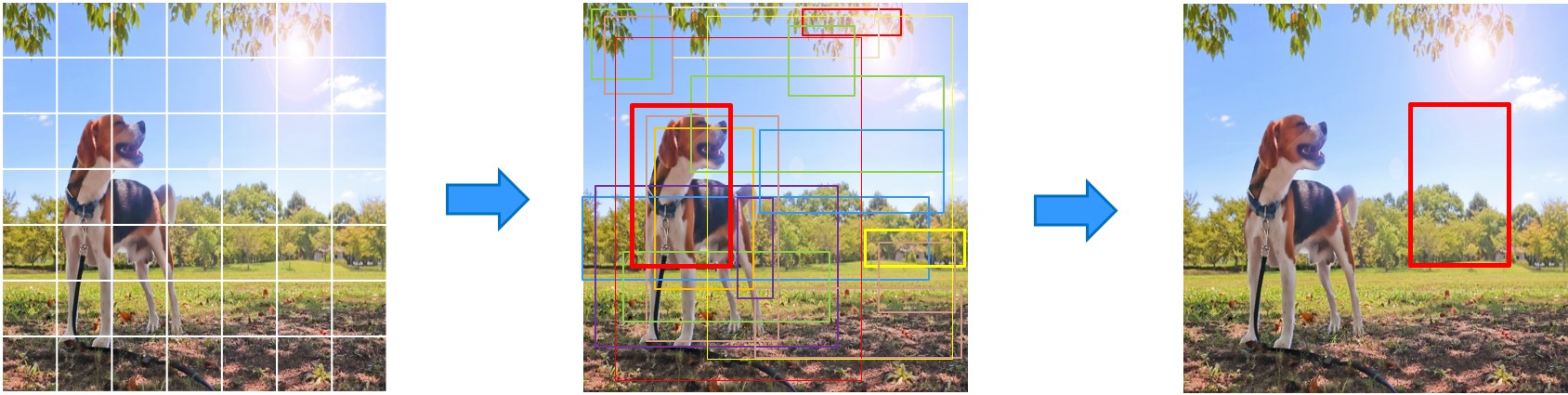
下一頁,我們來看物件偵測範例。
請按影片左下方,撥放紐
辨識出物件,加上框框標記物件位置。
所以說,物件偵測就是在找出畫面中物件及其位置囉?


YOU ARE RIGHT!
我明白物件辨識在幹嘛了!
不錯!
歷史演進
今天來看看有哪些物體辨識框架
物體辨識框架有很多種
物件辨識演進年代表
早在1943年類神經網路的演算法便已提出









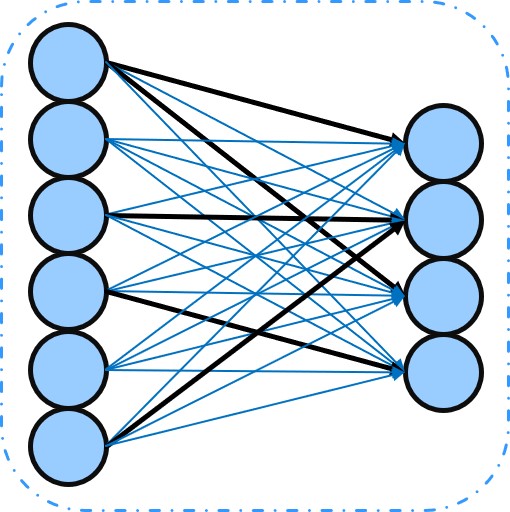
NN是現在許多影像辨識框架的老祖宗
每一個輸入的點是圖片的pixel,輸出則是物體種類
但因為將圖片變得平坦,而導致空間信息丟失了
沒錯,而且無法保留物體特徵
那該怎麼辦呢
就是CNN上場的時候了

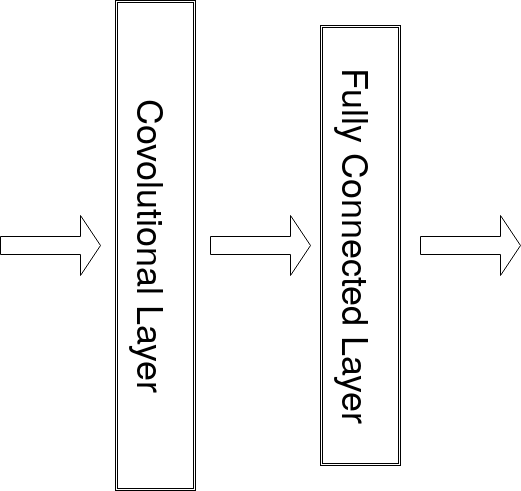

比NN多一個C,是什麼意思呢?
CNN的C是卷積的意思
所以是用卷積層取代部分全連接層囉!
透過大小不一的Sliding Window去尋找物體
之後將Sliding Window內的影像
送入卷積層萃取特徵,
最後再送入全連接層分類
不覺得每張圖片都要用
Sliding Window去掃描很浪費時間呢?
沒錯,而且Sliding Window
還要剛好符合物體大小
這時候就是R-CNN上場的時候了

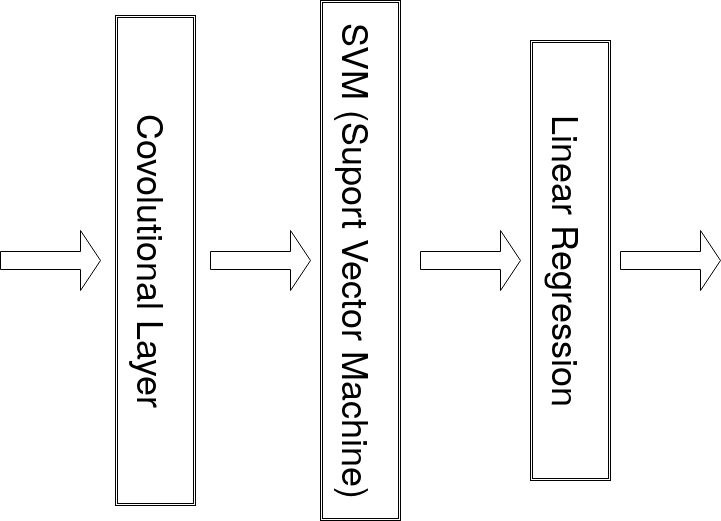
R-CNN候選區域的概念,加快了速度
將候選區域丟入卷積層,萃取特徵
再使用SVM向量機去判斷是物體還是背景
最後使用線性回歸調整 bounding box 的位置
這樣就可以把物體位置標出來了
但是每個區域的特徵好像不能共用耶
對阿,照理說物體可能出現在任何地方
所以說應該要讓每個候選區域共用彼此的特徵
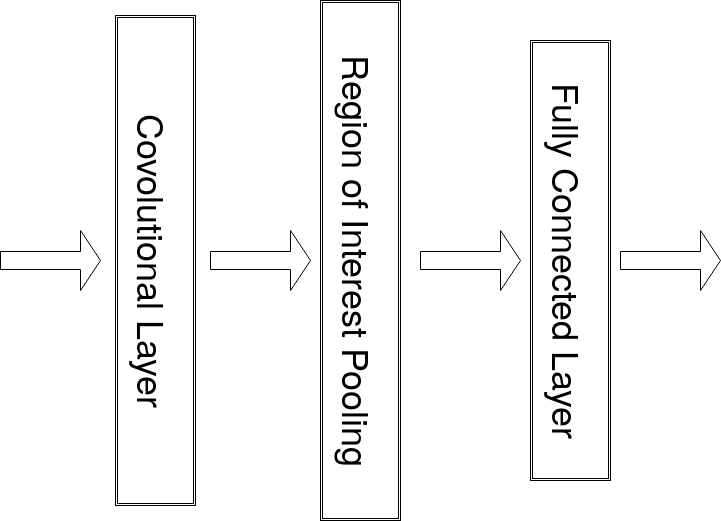
使用Region of Interest Pooling,
讓萃取出的特徵所有區域都能共用
不過要選候選區域,
何不直接在feature map上選呢?
對耶~
feature map 尺寸更小,速度更快
Faster R-CNN 提出了
RPN (Region Proposal Network) 的概念
就是使用anchor box
在 feature map 上做 sliding window
再接上原本的Fast R-CNN
因為選擇候選區域變快了,加快了整體速度
這時候有一個新的框架橫空出世

沒錯,就是YOLO
有別於R-CNN的物體分類和區域判定兩步驟,
YOLO直接把兩者合成一步驟
這就是YOLO比較快的秘訣
YOLOv1 不使用候選區域,
而是將圖片切成7x7x7大小,
每一格網格預測自己的 bounding box
每一個 bounding box再送入卷積層萃取特徵,
最後再送入全連接層做分類和確定 bounding box
因為帶有 grid cell 的空間訊息,
可以直接預測物體種類跟位置
這就是YOLO的一步到位
不過阿,YOLOv1 還是有缺點的
該怎麼說呢
由最後輸出的 tensor 得知,
所有 bounding box 共用所有物體信心分數
這樣會怎樣呢
這樣會導致每個 grid 只會預測一個物體
這樣兩物體中心很靠近時就預測不到了
沒錯,所以 YOLOv2 借鑒了Faster R-CNN,
從訓練集選出五個最合適的的 anchor box

而且每個 anchor box 信心分數是獨立的
沒錯,所以 YOLOv2 對於重疊的物體有更好的準確率
但 YOLOv2 網路變深不會導致信息丟失嗎?
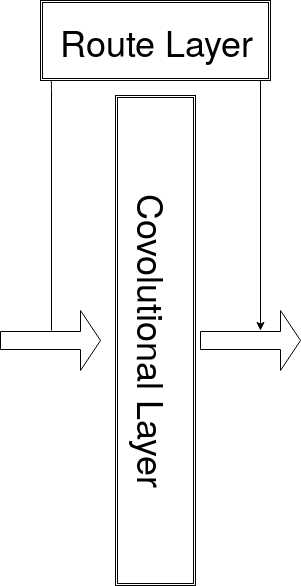
對此,YOLOv2 借鑒 ResNet,
增加 rout layer, 將淺層特徵連接到深層
這樣深層網路也能保有細節的特徵了
比較圖
技術介紹
類神經網路 NN
什麼是類神經網路?
類神經網路(Neural Network,簡稱NN),
它就像人類大腦的思維去辨別物件,
由物件的部分區塊去判斷是什麼種類,
它是物件偵測的發展起源
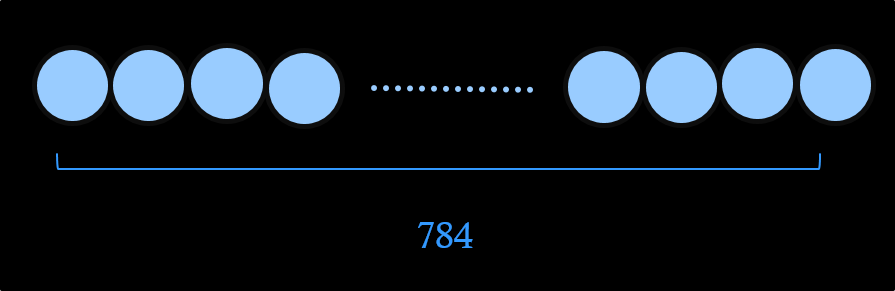
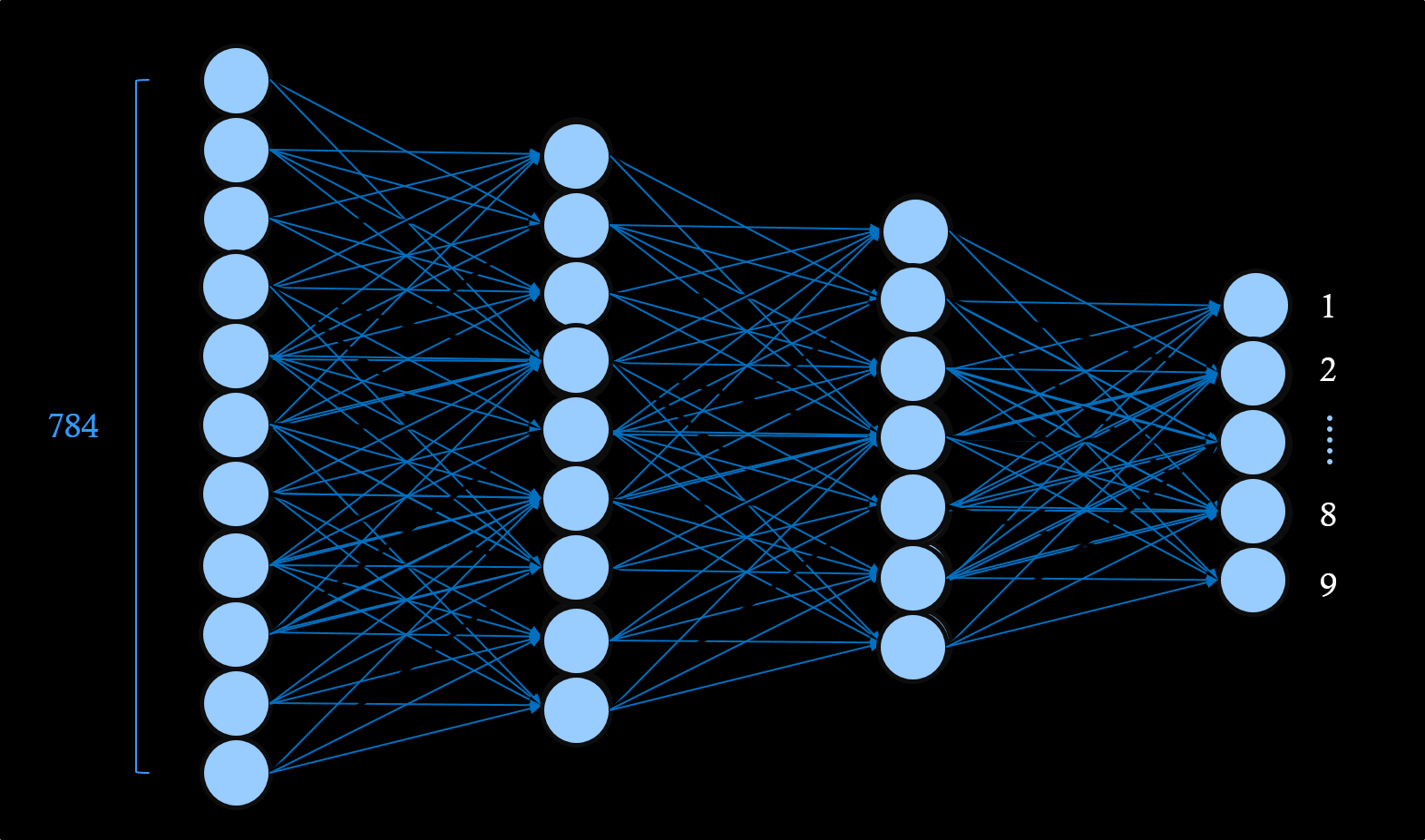
以下的圖片,是一張數字9的圖像,
它是怎麼進行處理的?

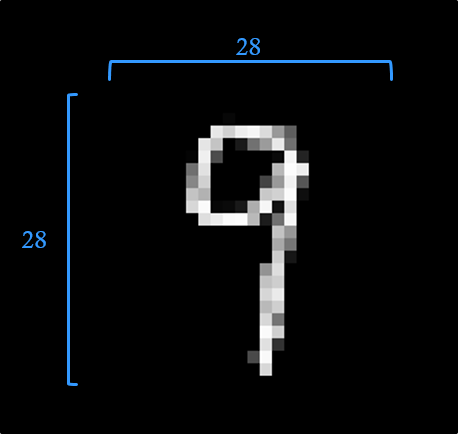
它是一張28像素乘以28像素的圖片(784像素),
是以像素的方式輸入
接下來呢?
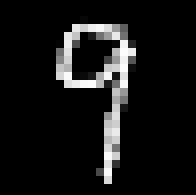
然後把這些像素重新排成一列
接下來呢?

轉個方向,將橫向轉成直向
這個圖片好複雜喔,是什麼?
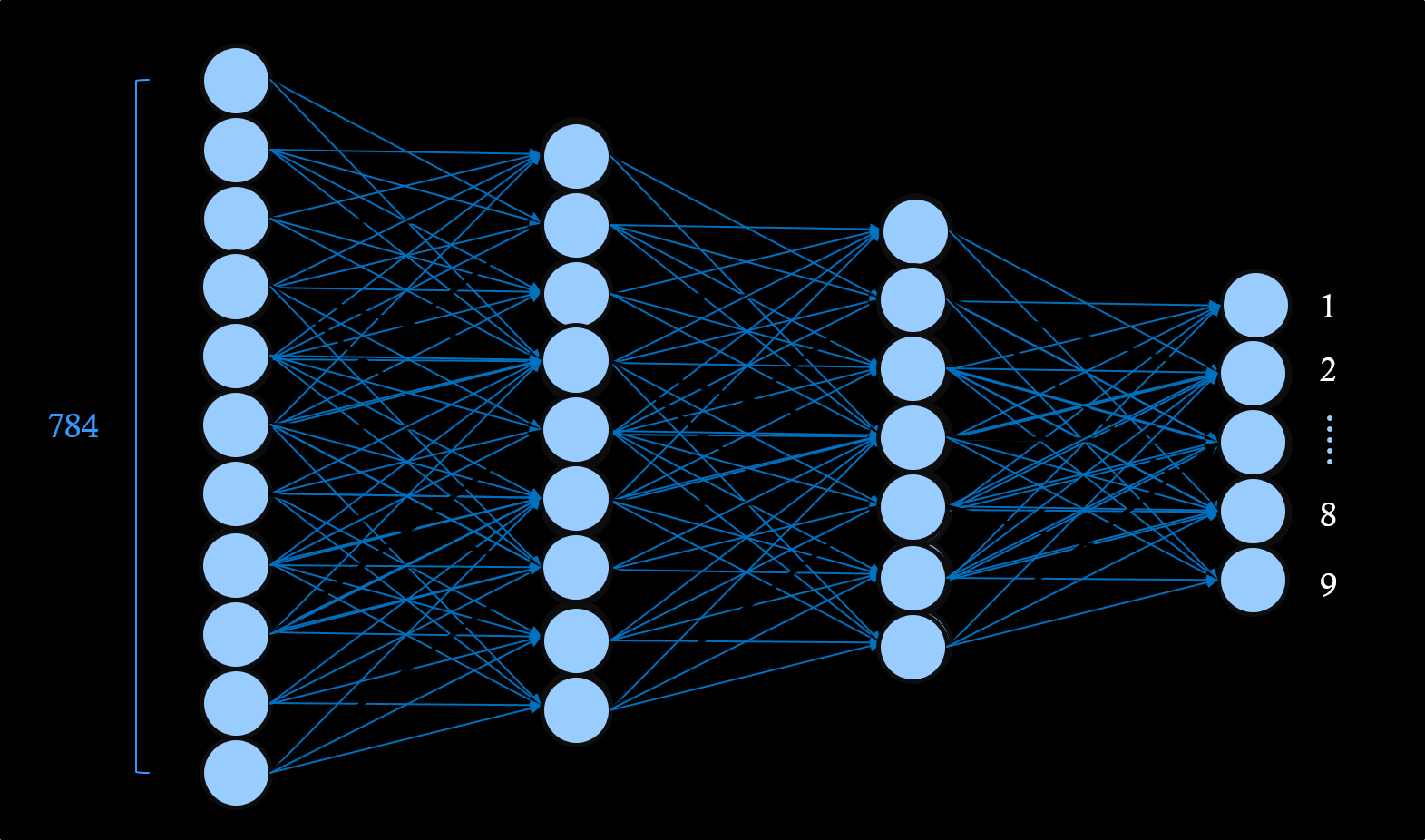
放進類神經網路中,最左邊是輸入的像素,
經過中間兩層是隱藏層,最右邊是分類種類,
這樣最右邊就是分類數字1到9
數字0變成好多小區塊
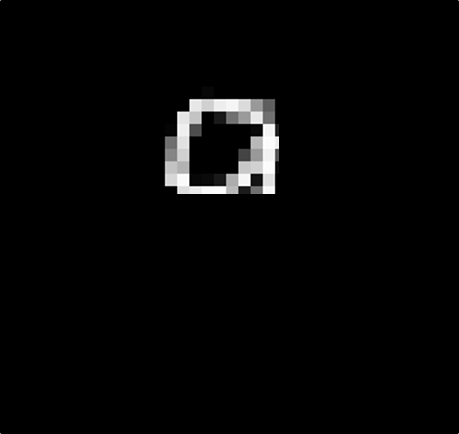
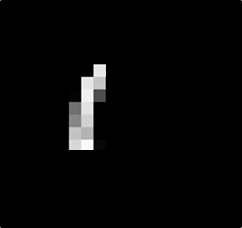



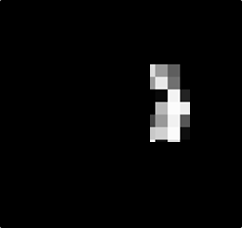
其中我們可以發現大部分的數字可以由其他
細節組成,數字0的部分,我們可以拆解成這樣
數字1變成好多小區塊
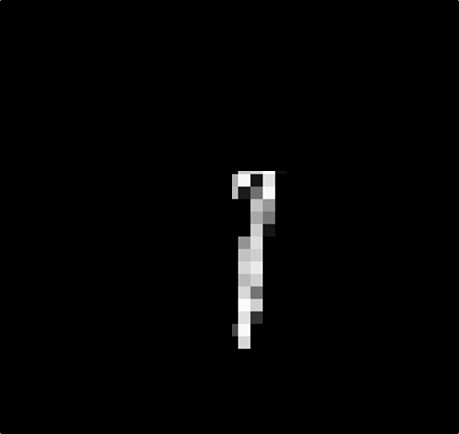
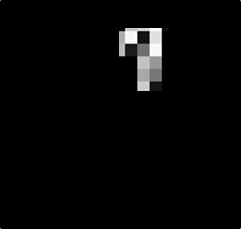
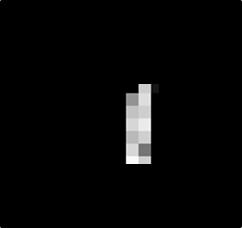

數字1的部分也是相同的,可以分為多個區段
數字9在視覺上可以想像成
數字1加上數字0的合併
沒錯!你真聰明
上述運作流程是在隱藏層處裡的嗎?
對阿! 在隱藏層從中找尋細節,
到最後一層就可以辨識出它是哪個數字。
我學會了!像是這個獅子,
可以從中找到很多的細節,像是這樣


沒錯!你真聰明
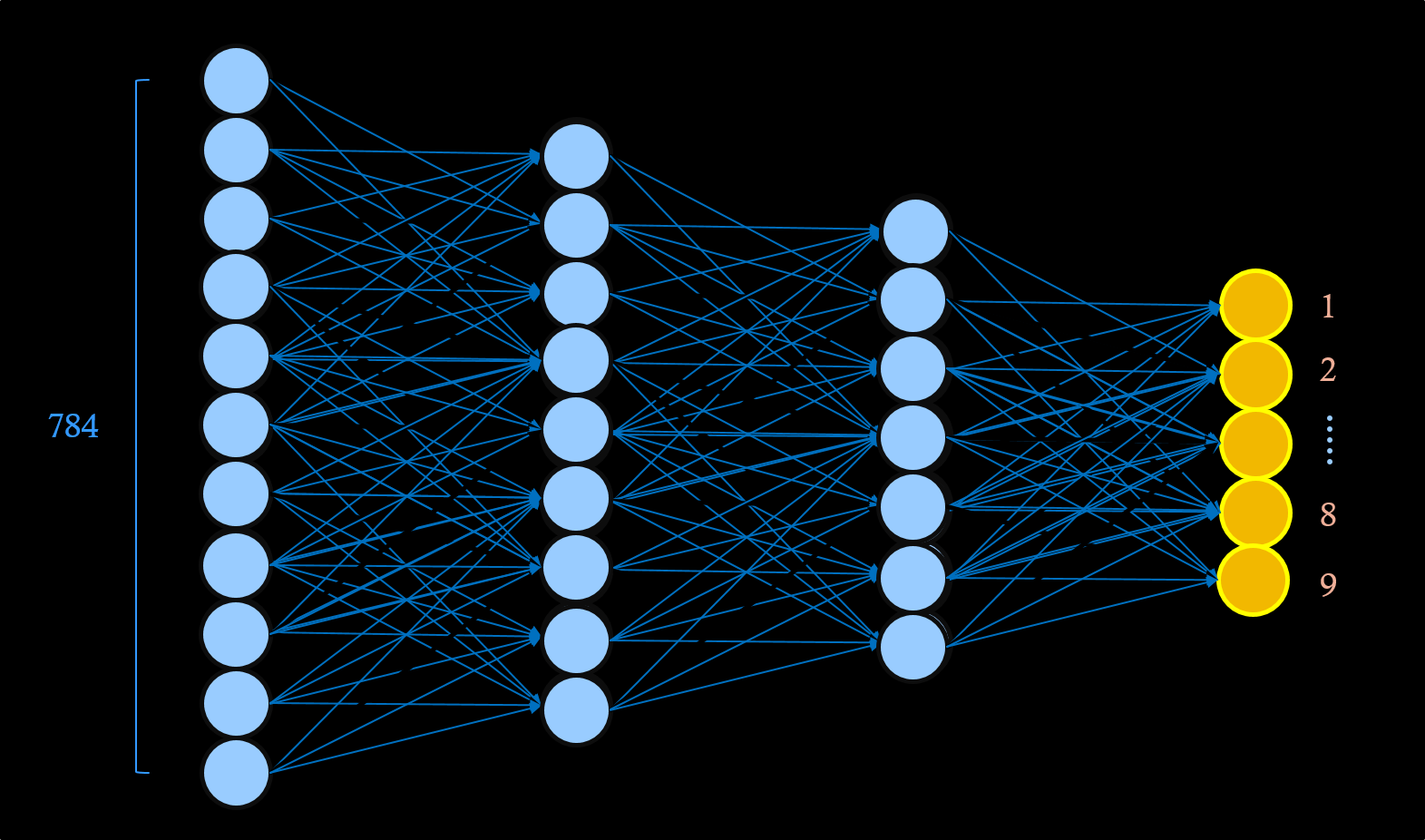
NN->FCN
可以轉換這種形式去呈現類神經網路,僅能一種物件輸入

最右邊的圖是各種種類的機率
在類神經前面加上卷積,這樣就是卷積網路

輸入單一物件圖就可以輸入,
像是只有貓咪一個物件的圖像
全卷積網路,整合了卷積層和池化層


這樣可以從多物件的原圖輸入
Sliding Window
Sliding Window就像你從管子中看一隻花豹,由左上至右下搜尋它

那管子太大或太小就找不到花豹了
沒錯,如果管子太小,那就只能看到花豹的局部斑點!

而且...你不一定知道花豹在哪!
所以我們只能用管子,從頭到尾掃過一遍,而且要祈禱管子大小,剛好符合豹的大小

也就是用各種不同大小的框框去,
窮舉法,掃描整個畫面,然後去判斷是何物。
卷積神經網路CNN
右右~CNN做了什麼事情?
它以類似人類判斷物體的方式,以特徵優先判斷
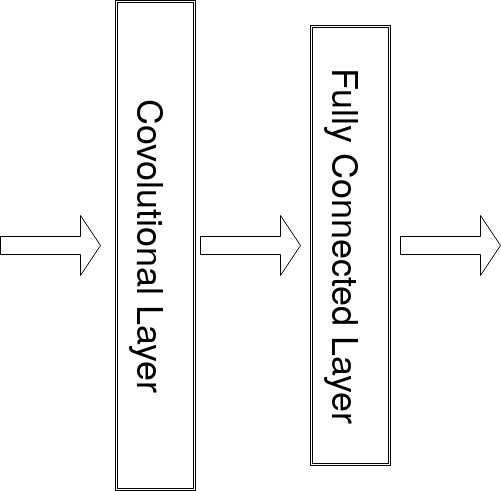
主要架構有卷積層(Convolution Layer)、池化層
(Pooling Layer)及全連接層(Fully Connected Layer)
卷積層中使用Sliding Windows方式找特徵
那這幾層架構分別做了什麼?
卷積層,它將輸入的圖片轉換成像素,來進行運算
透過這樣的方式,生產出特徵圖
右右~可以講詳細一點嗎?


你看左邊的圖片作為輸入圖片,這一層的
卷積是找出水平特徵,而右手邊輸出的圖片,
明顯可以看出僅有水平特徵
喔~那池化層做了什麼?
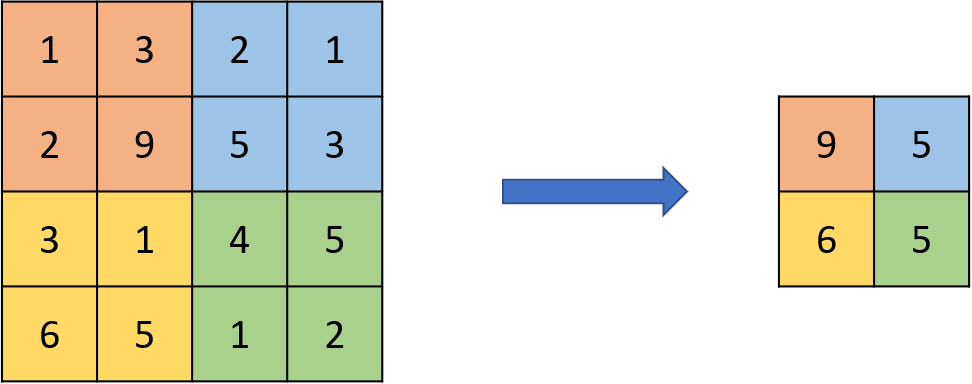
池化層,將卷積層的特徵取出,選取數值最大的
如此以來讓特徵更明顯,同時還可以縮減
模型的大小,提高計算速度
全連接層接下來是進行辨識嗎?
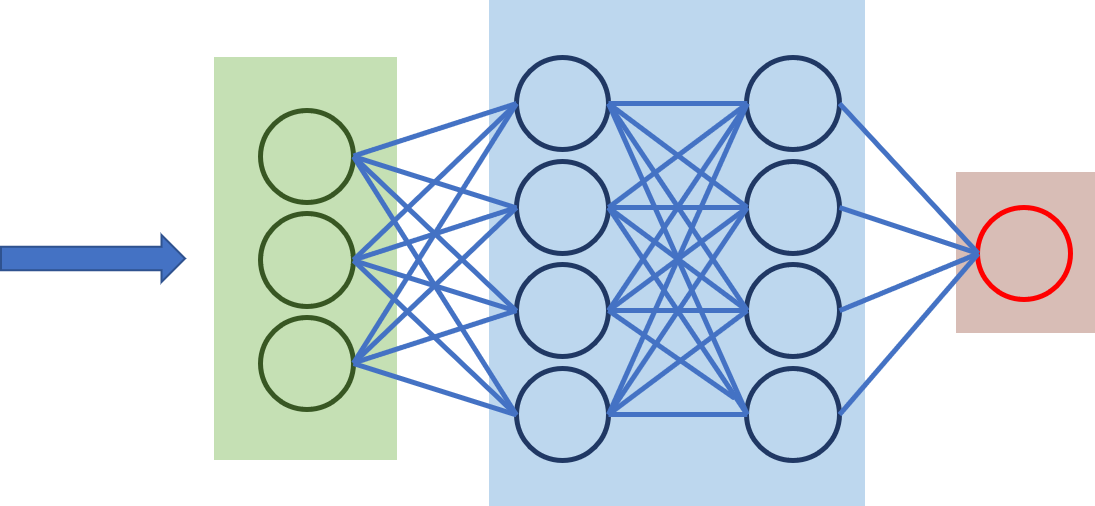
是阿~
全連接層,全連接層跟類神經網路做相同的事情
接續池化層的資料,將明顯的特徵圖
輸出至全連接層,進行分類的預測
R-CNN 系列
R-CNN又做了什麼?
步驟一 產生出2000可能區域(Region proposal)
步驟二 每一個region proposal所選出丟入CNN
步驟三 利用SVM(Support Vector Machine)分類器區分屬於哪類
步驟四 線性回歸模型校正bounding box位置
Fast R-CNN步驟為何?
步驟一 產生出2000可能區域(Region proposal)
步驟二 region proposal進行ROI pooling,接著輸出到CNN
步驟三 再輸出到全連接層運算去分類
Faster R-CNN又差在哪裡?
步驟一 透過CNN取得feature map
步驟二 利用RPN網路將feature map放入全連接層運算,
輸出較低維向量的特徵
步驟三 將低維向量輸出至兩層全連接層,合併後進行分類
YOLO
右右~一直說YOLO物件辨識,
我已經知道物件辨識是什麼了!
但是YOLO到底是什麼意思啊?

就是You Only Look Once,
你只看一次的意思!
喔~那是誰提出這個方法的啊?

作者是Joseph Redmon,
他是華盛頓大學計算機科學博士生
是基於CNN提出了一種精確的、即時性
的方法來實現的物件辨識
所以YOLO可以辨識很多東西嗎?




目前可以辨識的類別有20種
包含最基本的人、鳥、貓、牛、狗、馬、羊,
還有交工工具:飛機、自行車、船、汽車...等
右右那它是怎麼運作的?
運作流程如下
步驟一 影象縮放:將圖像縮放置特定大小
步驟二 執行一個卷積神經網路:在神經網路中,
同時進行卷積運算及anchor box的分類運算
(卷積運算使用的框架是Darknet-19)
步驟三 偵測結果:使用NMS篩選,以此選出最佳結果
Anchor Box
這是 yolo嗎 ?
不錯
上圖是 yolo的檢測流程
這些是什麼框框 ?
是anchor box阿
左左是第一次看到嗎 ?
對阿~ 好新奇喔
在yolov2的設定檔裡,
原始數據 : anchors = (0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434), (7.88282, 3.52778), (9.77052, 9.16828)
anchor box長寬是相對於input image的比例大小,
所以是與image大小相關的喔 !
有興趣學習yolo裡的 anchor box知識嗎?
好阿! 好阿!
anchor box是怎麼應用在yolo的程式上 ?
步驟 1 : 我們把feature map切成13x13個網格
步驟 2 : 把每個網格的中心當為錨點(anchor point)
步驟 3 : 將5個anchor box套入網格作計算
全部網格都要做步驟3的計算喔!
老師 您可以示範給學生看嗎 ?
以這個網格為範例
5個 anchor box分別套入網格作計算
計算後,就會得到在區域中是否包含物體的信心值
原來有那麼複雜的計算程序喔~
不用擔心,老師一步一步帶你了解yolo
對了! 我們anchor box計算的值跑去哪裡了?

為了要解釋Tensor的產生,
先讓你了解一個 anchor box會儲存哪些資料吧?
1個 anchor box除了儲存置信度外
還包括了,anchor box的長寬、座標和類別資訊
ab1 這裡代表的是什麼呢?
我們簡稱 anchor box 1為 ab1
然而,一個網格計算出 5個anchor資料
也就是13x13個網格會產生 13X13x5個資料量
老師!老師! 你剛剛提到的"Tensor"又是什麼呀!
沒錯! 我正要提到所謂的Tensor
我們把一個網格的資料量稱為Tensor
Tensor 儲存了5個 anchor box計算的資訊,所以資料深度是 5x25
喔~ 原來這就是Tensor阿!
最後,我們回顧一下輸入圖會產生的Tensor資料
因為一張圖被切割成 13x13個網格
又因為一個Tensor 資料深度是 125,所以一張圖的總資料量是 13x13x125 !
今天學習的東西好多喔!
老師~老師 可以幫我統整一下嗎?
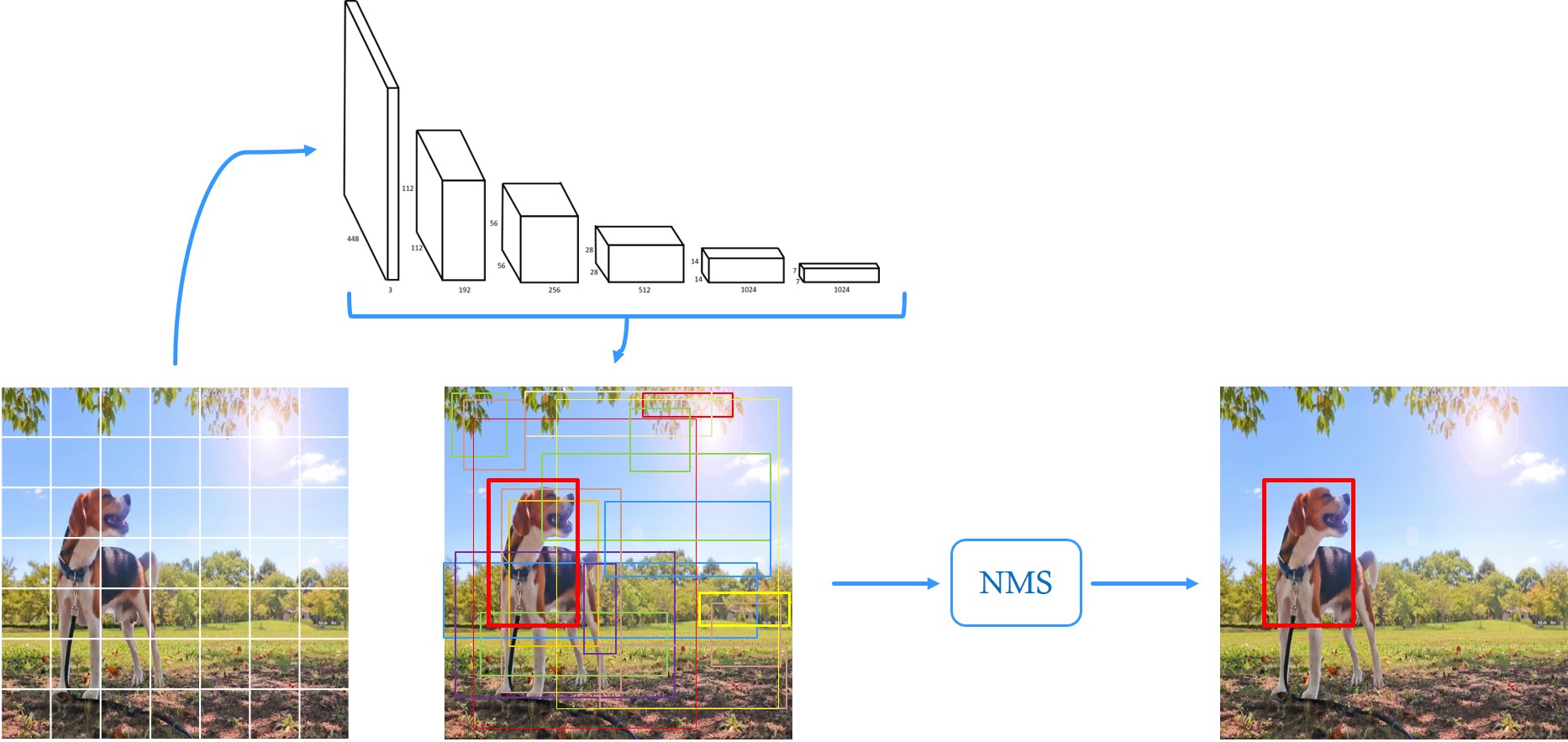
我們上方看到Darknet-19的架構,是yolo的網路骨幹
yolov2全部都是卷積層,輸出就是為了跑出中間的"類別框框圖"
最後經過 NMS 來"篩選掉重覆和不可能的框框"
就能得到我們的預測圖囉!
Darknet-19
Darknet是什麼東西啊?
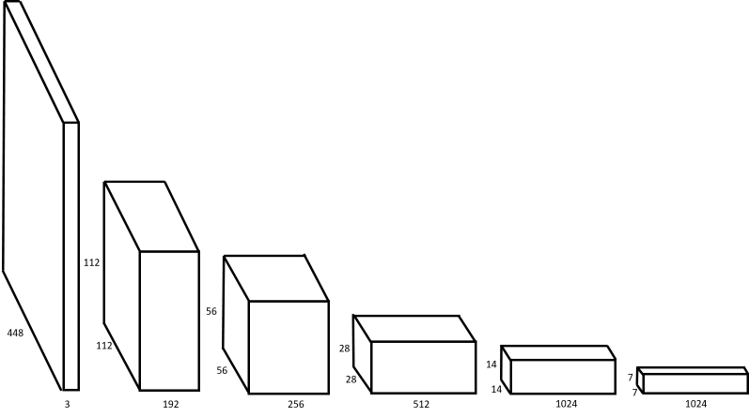
以上是它的縮圖,它是卷積網路的架構,
Darknet-19是以原先的Darknet為基礎,
移除最後的類神經網路,再加上一些修改所得到的
那它在物件辨識有什麼幫助?
以它的架構進行卷積運算
我們是透過卷積網路取得特徵圖,
在獲得特徵圖的同時,進行anchor box的動作
因此,在完成運算的時候,
我們就可以知道被辨識的物件是什麼
右右~能展示給大家看嗎?
這裡有一個視覺化展示的網站
https://kagu82104.github.io/thesissystem/
system/example8/index.html
適合有學習過深度學習的同學
有興趣也可以看一下!
請看下一頁展示頁面
哇~這樣就可以知道它運作時,圖片在過程中的變化了
對阿,透過此系統,我們在看物件辨識的結果時,
可以由圖像呈現,讓我們清楚知道過程做了什麼事情,而造成最後的結果
YOLO v2
可視化展示系統
可以展示一下視覺化系統嗎?
好啊,請看下一頁,他是展示YOLO v2的
特徵圖與權重圖可視化
前面說到darknet-19,它流程又是如何?
我們把darknet-19網路架構用圖像的方式,
一個方塊接續著下一個,以此呈現出卷積運算的輸入及輸出圖像格式。
還有其他特別的嗎?
請看下一頁,利用3D的動態圖示呈現
卷積運算過程
好酷喔!
對阿,還有tensor及anchor box互動式的視覺化模組,可以試試看,目前為測試版本
比較&特色
| 技術 | R-CNN | Fast R-CNN | Faster R-CNN | YOLO | YOLOv2 |
FPS |
0.05 | 0.5 | 7 | 45 |
40 |
mAP |
66 | 70 | 73 | 63 |
78 |
| 作者 | Girshick |
Girshick |
Girshick |
Redmon |
Redmon |
照片 |
 |
|
 |
||
Year |
2014 | 2015 | 2016 | 2016 | 2017 |
論文 |
 |
|
|
|
|
與其他方法相比,YOLO 有何獨到之處?
YOLO 速度快!
請看下一頁比較表。
哇~~~ YOLO 比其他方法快了六倍!
YOLO 每秒鐘可以處理 40 幀畫面!
比起 R-CNN 系列,YOLO 準確度,如何?
YOLO 辨識準確度可達 78 mAP。
請看下一頁比較表。
在準確度的表現呢?
YOLO 沒有犧牲辨識準確度。
相較於其他方法,YOLO 有何獨特之處?
在FPS大於20幀時,
是一般人類眼睛看到順暢的畫面,
而且只有YOLO在FPS大於20幀,
所以目前方法僅 YOLO 可以達成即時辨識並呈現
應用
Case 2 - 甭舉手、看鏡頭(自動點名APP)
Case 3 - 影片人物辨識
Case 4 - 書法帖筆畫辨識